November 15, 2024
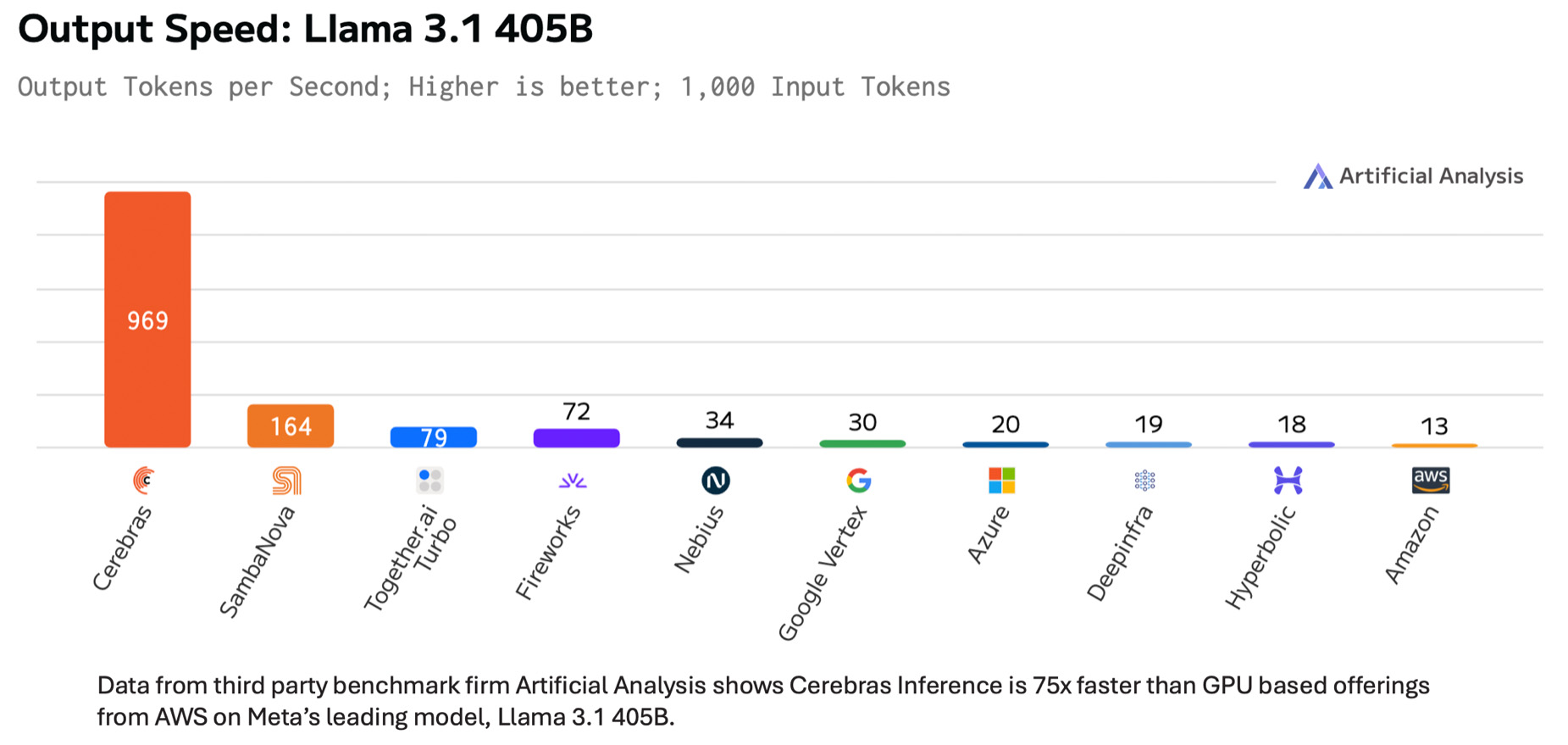
Cerebras Systems has achieved a new performance milestone with Llama 3.1-405B, Meta AI’s leading frontier model. Cerebras Inference delivered 969 tokens per second, up to 75 times faster than GPU-based hyperscaler offerings, and achieved an industry-leading latency of 240 milliseconds for the first token. This breakthrough enables real-time responses from large language models for the first time, revolutionizing AI inference capabilities.
Powered by the Wafer Scale Engine 3 (WSE-3), the Cerebras CS-3 system offers unparalleled speed, capacity, and low latency, with 7,000x more memory bandwidth than Nvidia’s H100. This allows Llama models to run complex reasoning tasks far longer, significantly improving accuracy on demanding tasks like math and code generation. The Cerebras Inference API ensures seamless integration with OpenAI’s Chat Completions API.
Currently in customer trials, Cerebras Inference for Llama 3.1-405B will be generally available in Q1 2025, priced at $6 per million input tokens and $12 per million output tokens. Free and paid versions of Llama 3.1 8B and 70B are also available. Visit www.cerebras.ai for details.