Welcome to an insightful discussion on the DeepSeek paper, where we dive into the intricacies of inference learning and its promising future through reinforcement learning. Join me as we uncover the academic value of DeepSeek and how it addresses the gaps in large language models.
Introduction to DeepSeek
DeepSeek represents a significant leap in the development of large language models. It stands out due to its innovative approach, leveraging reinforcement learning to address existing gaps in language understanding. This model is not just another iteration; it is a foundational shift in how we perceive and utilize language models.
At its core, DeepSeek aims to refine the interaction between language and its underlying structures. By doing so, it enhances the model’s ability to learn and adapt, creating a more robust system capable of understanding complex queries and providing accurate responses.
The Message of the Presentation
Two primary messages emerge from the exploration of DeepSeek. First, it reveals the inherent gaps within traditional language models. These gaps can lead to misunderstandings or inaccuracies in language processing. Second, and perhaps more crucially, it demonstrates that reinforcement learning can effectively fill these gaps, enhancing the model’s performance and reliability.
This dual message underscores the importance of innovation in the field. By recognizing and addressing these shortcomings, researchers can create models that not only perform better but also push the boundaries of what is possible in language processing.
Review of Related Papers
DeepSeek is part of a broader research landscape, with numerous related papers that contribute to its development. A review of these documents reveals four primary lines of inquiry:
- DeepSeek Versions: V1, V2, V3, and R1, each building upon the last to enhance the model’s capabilities.
- Vision Language Models that integrate both visual and textual data, providing a more comprehensive understanding of information.
- Programming and coding applications, showcasing the versatility of DeepSeek in various domains.
- Mathematical problem-solving, highlighting the model’s ability to tackle complex calculations and logic problems.
Each of these areas not only supports the development of DeepSeek but also illustrates the diverse applications of reinforcement learning in enhancing language models.
DeepSeek Versions: V1 to R1
The evolution of DeepSeek from V1 to R1 marks a journey of continuous improvement and innovation. Each version has introduced unique features and enhancements, culminating in the current R1 model, which represents a paradigm shift in how language models are trained.
V1 set the foundation with its open-source approach, signaling a commitment to accessibility and collaboration. V2 expanded on this by incorporating advanced techniques like Group Reinforcement Learning (GRP), allowing for more effective training methodologies.
V3 gained recognition for striking a balance between size and performance, while R1 further advanced the model by learning without traditional fine-tuning, relying solely on reinforcement learning. This shift showcases a novel approach in which the model learns directly from interactions, enhancing its understanding and adaptability.
The Role of Vision Language Models
Vision language models play a crucial role in the DeepSeek framework. By integrating visual information with language processing, these models create a more holistic understanding of context and meaning. This synergy allows the model to interpret and respond to queries with greater accuracy and relevance.
For example, a vision language model can analyze an image and generate descriptive text, or conversely, interpret text to generate visual representations. This capability is essential for applications that require a nuanced understanding of both visual and linguistic data.
The Importance of Coding Models
Coding models represent another vital aspect of DeepSeek’s versatility. As programming and software development continue to evolve, the ability for language models to understand and generate code becomes increasingly important. DeepSeek’s coding capabilities allow it to assist developers by providing code suggestions, debugging help, and even generating entire code snippets based on user input.
By leveraging the principles of reinforcement learning, these coding models can learn from interactions, improving their suggestions and responses over time. This not only enhances productivity for developers but also contributes to the overall advancement of AI in programming.
Mathematical Problem Solving with DeepSeek
One of the standout features of DeepSeek is its ability to solve mathematical problems effectively. This capability is rooted in the model’s advanced learning techniques, which allow it to tackle complex equations and logical reasoning tasks.
Through reinforcement learning, DeepSeek can refine its approach to problem-solving, learning from both successes and failures. This iterative process enables the model to develop strategies for various types of mathematical challenges, ultimately improving its accuracy and efficiency.
The implications of this feature extend beyond academic applications; they also encompass real-world scenarios where accurate calculations and logical reasoning are crucial. By integrating mathematical problem-solving into its repertoire, DeepSeek positions itself as a more comprehensive language model, capable of addressing a wider range of queries.
Discovering the Gaps in Large Language Models
Large language models, despite their impressive capabilities, exhibit notable gaps. These gaps often manifest in their understanding of context and reasoning abilities. For instance, certain mathematical operations may be performed inaccurately, revealing a fundamental flaw in how these models process information.
Research has shown that when faced with complex tasks, these models can falter. They may rely on heuristic shortcuts rather than engaging in genuine reasoning. Identifying these shortcomings is crucial for further development and refinement.

Implications of GPT-4V Findings
The findings from the GPT-4V model have significant implications for the future of language processing. It revealed that even when trained on vast datasets, models can struggle with specific tasks, particularly those requiring visual context.
This raises questions about the validity of their training processes. For instance, models may perform well on standard text-based queries but fail when images are involved. This inconsistency highlights the need for more robust training methodologies that encompass various forms of data.

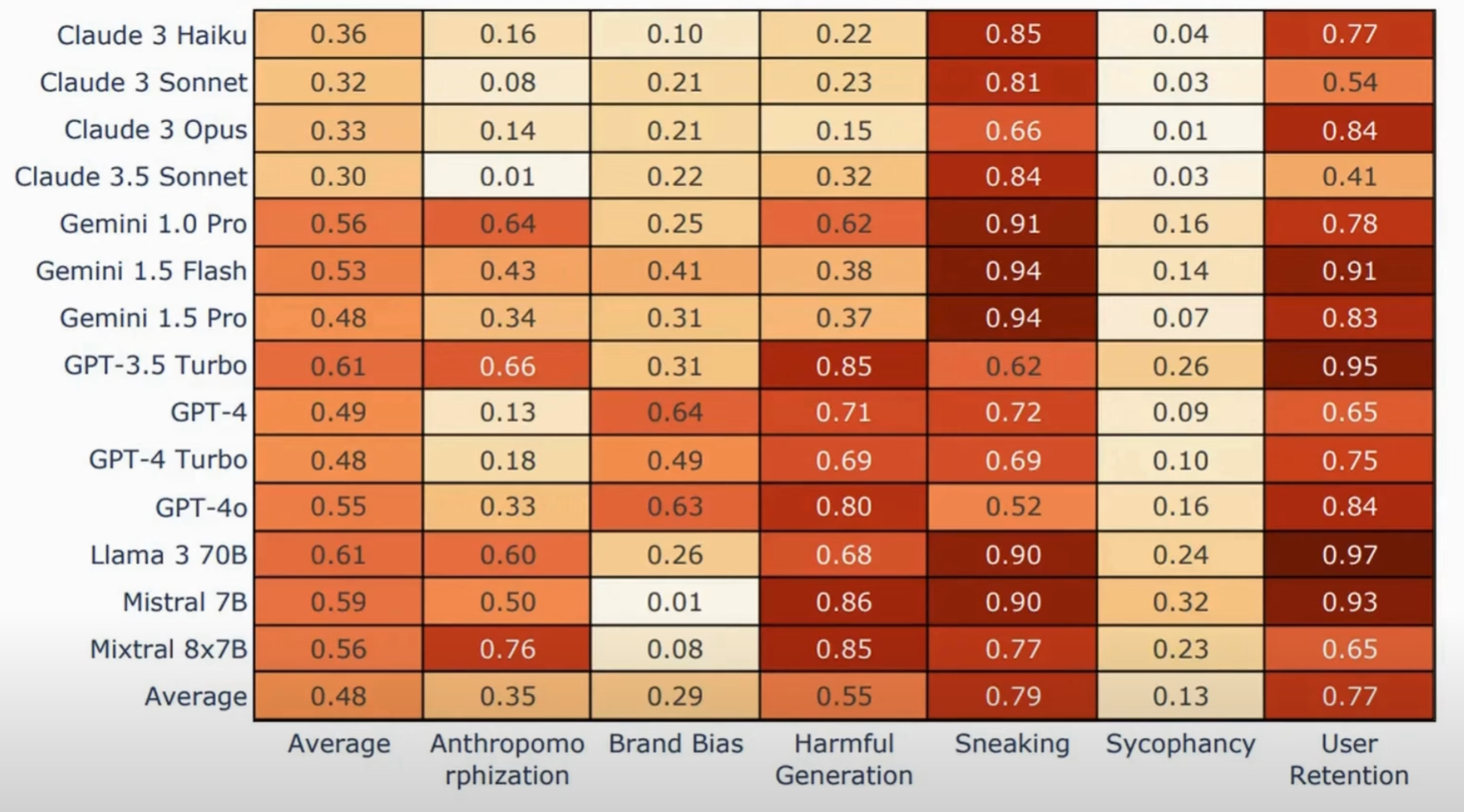
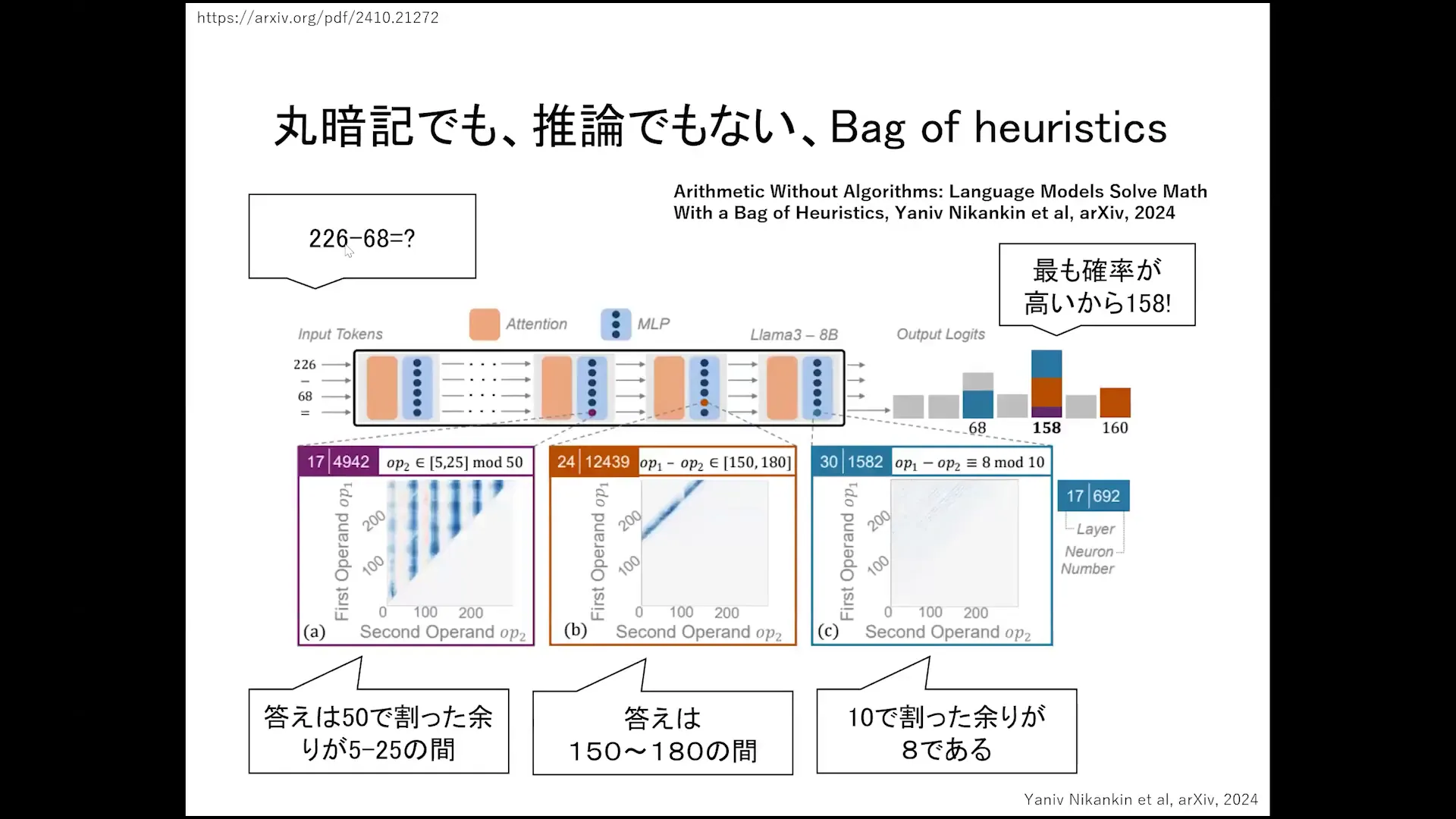
The Heuristic Models and Their Findings
Heuristic models provide a fascinating lens through which to examine language processing. These models often utilize shortcuts to arrive at conclusions, which can lead to unexpected results. A notable example is the discovery of the “Bag of Heuristics” phenomenon, where models generated responses based on probability distributions rather than logical reasoning.
When researchers analyzed simple arithmetic tasks, they found that models would often produce answers that deviated from expected outcomes. This highlights the importance of understanding not just what these models can do, but how they arrive at their conclusions.
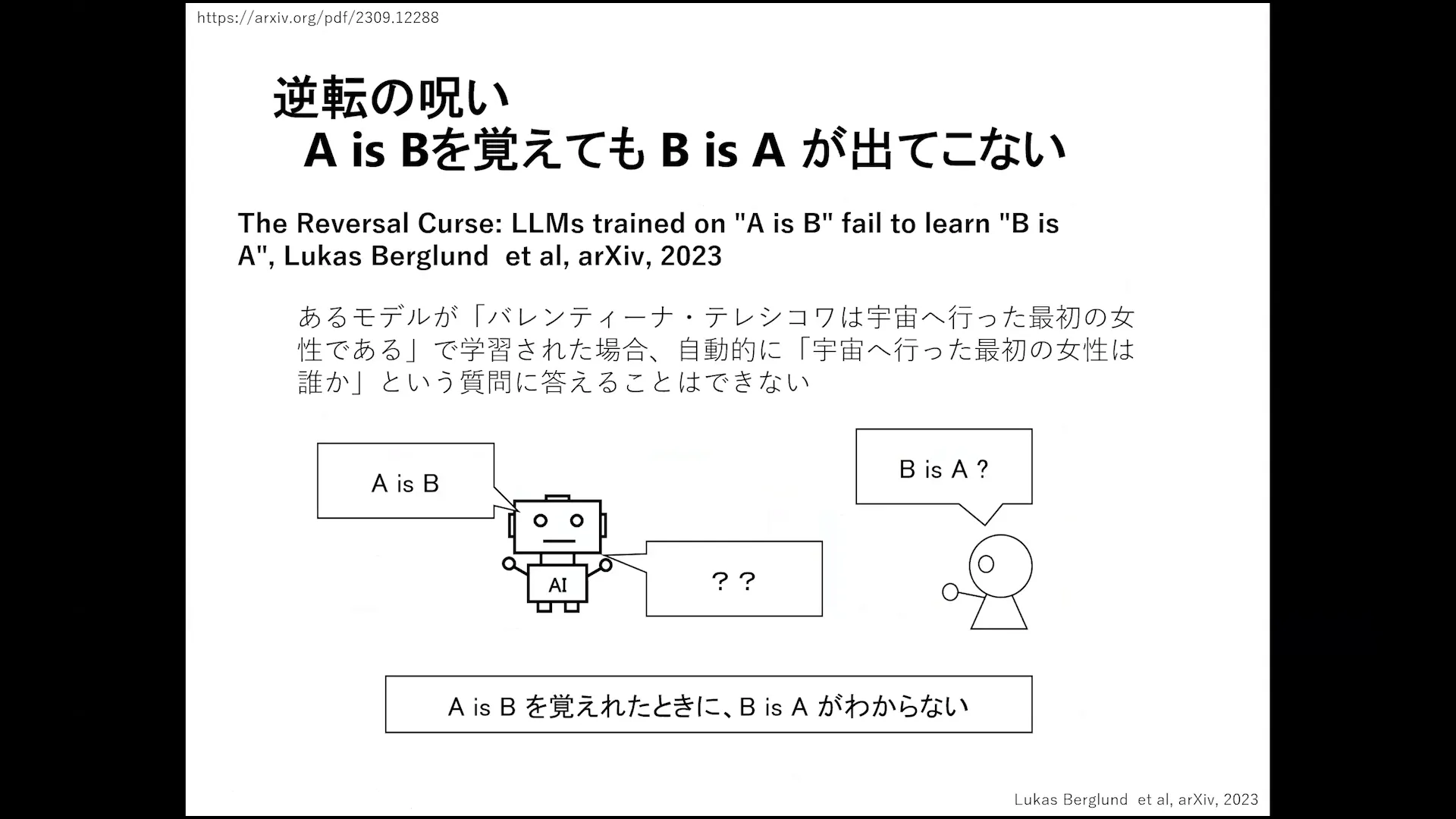
The Challenge of Reverse Search
Reverse search presents a unique challenge for large language models. These models struggle with retrieving information in a reverse manner, often leading to incomplete or incorrect answers. For example, even when they possess knowledge about a subject, they may fail to connect the dots when asked to provide information in reverse order.
This limitation underscores the necessity for improved algorithms that can handle complex queries more effectively. Addressing this issue is vital for enhancing the overall reliability of language models.
Preventing Gaps in Inference Learning
To prevent gaps in inference learning, it’s crucial to develop comprehensive training datasets that cover a wide range of scenarios. By incorporating diverse examples, models can learn to navigate various contexts more effectively.
This proactive approach not only enhances the models’ learning capabilities but also reduces the likelihood of errors in reasoning. Continuous evaluation and iteration of training methods will be essential in closing these gaps.
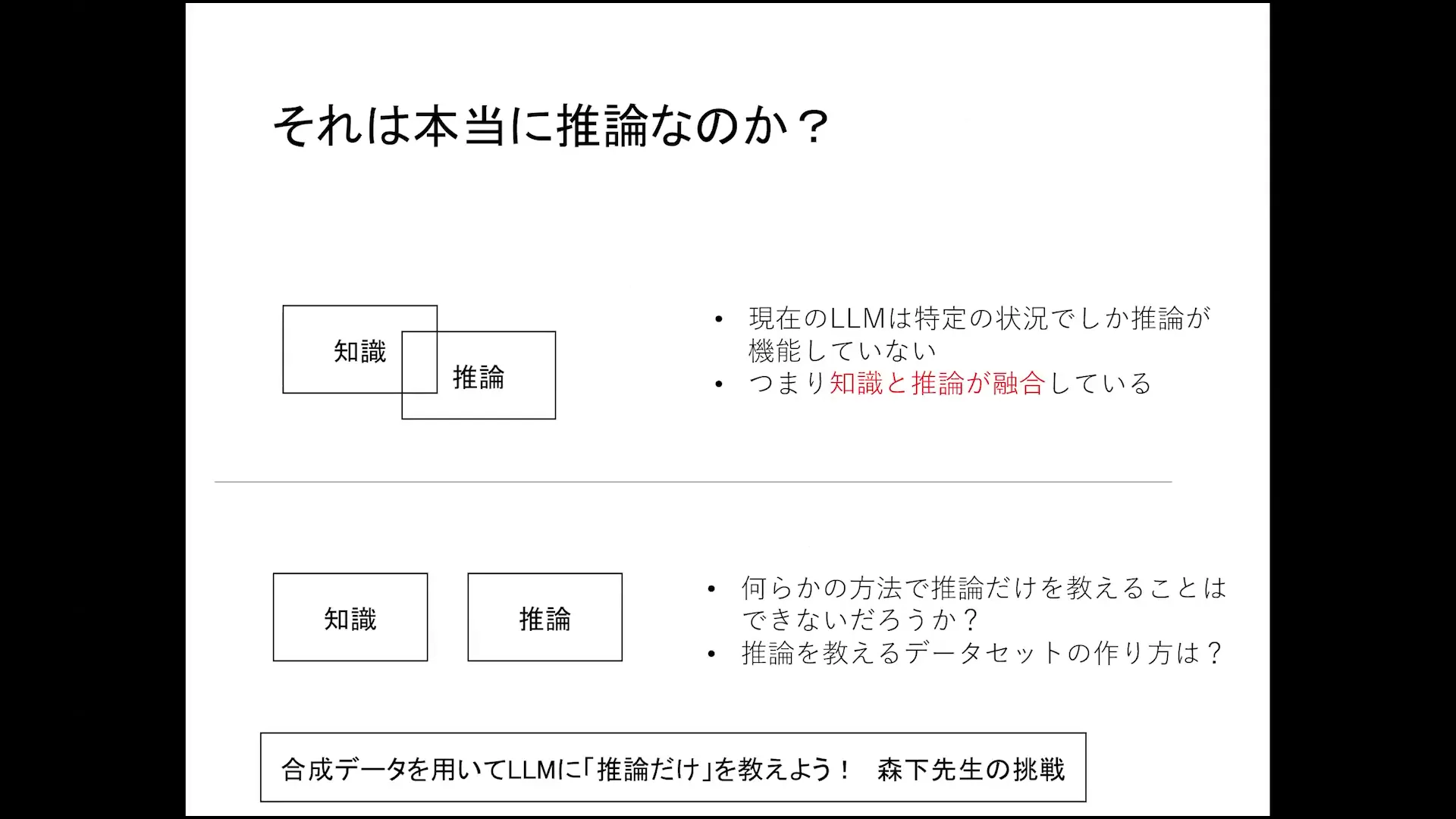
Creating Synthetic Data for Reinforcement Learning
Synthetic data plays a pivotal role in reinforcement learning. By generating data that simulates real-world scenarios, researchers can train models in controlled environments. This method allows for the exploration of various strategies without the constraints of real-world data limitations.
Moreover, synthetic data can help fill gaps in existing datasets, providing models with the necessary variety to improve their performance across different tasks. As researchers continue to innovate in this area, the potential for enhanced learning outcomes becomes increasingly promising.

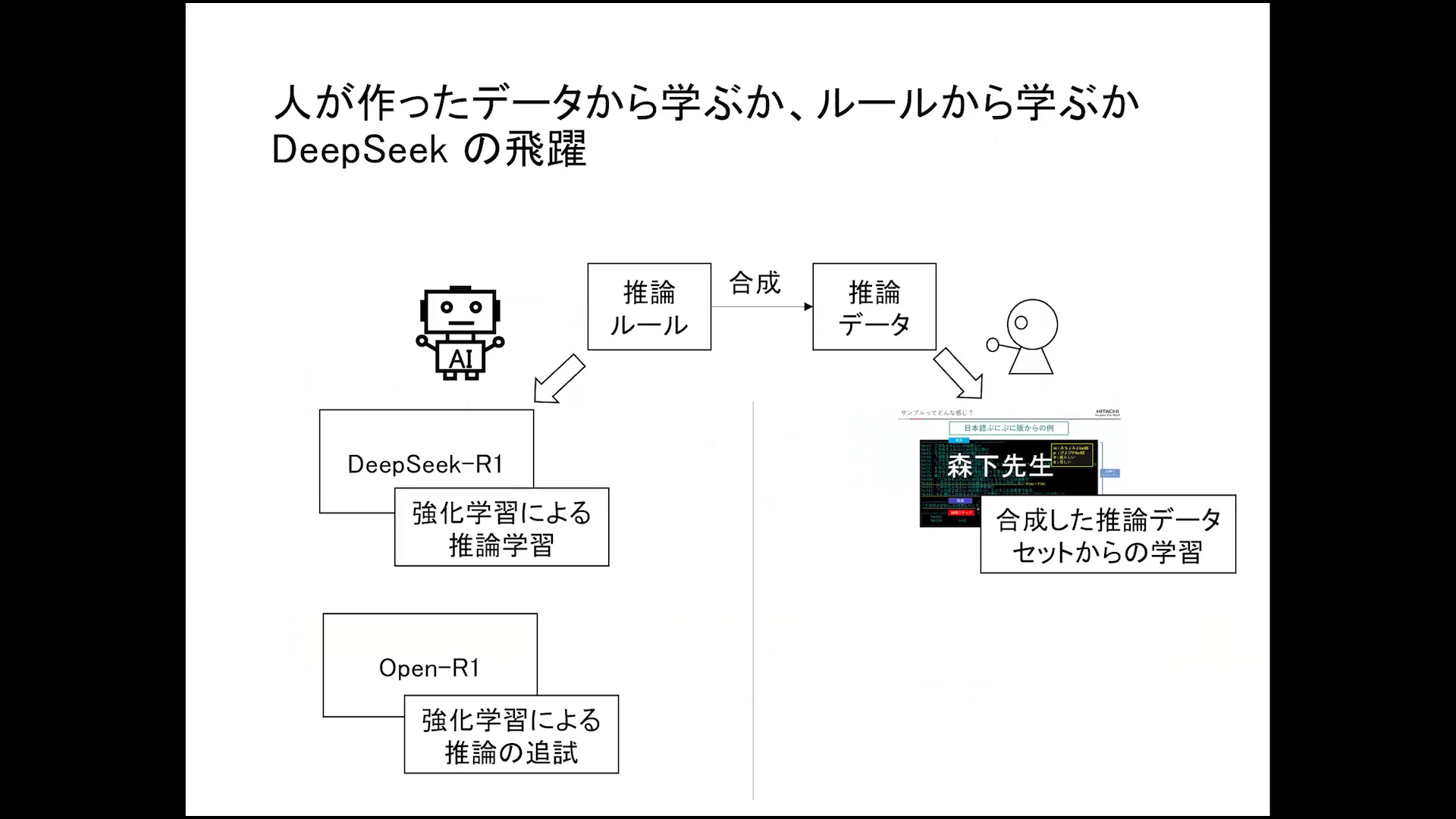
The Role of Synthetic Data in Learning
The integration of synthetic data into learning processes can significantly enhance model performance. By providing varied scenarios and challenges, synthetic data helps models develop robust reasoning skills. This approach is particularly beneficial in areas where real data is scarce or difficult to obtain.
Additionally, synthetic data can be tailored to address specific learning objectives, allowing for targeted training that aligns with desired outcomes. As we move forward, leveraging synthetic data will be crucial in refining the capabilities of large language models.
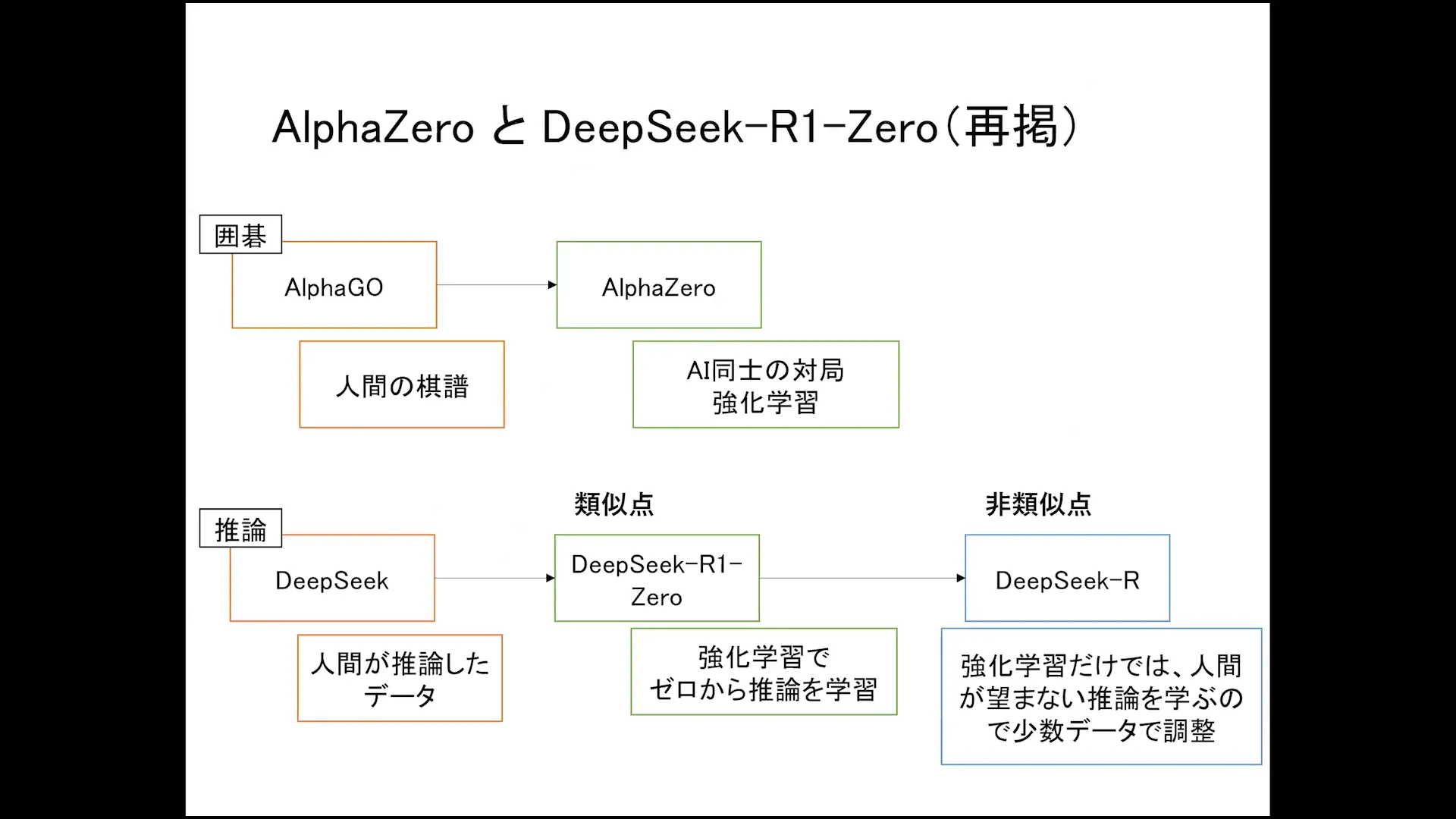
Exploring the Future of Large Language Models
The landscape of large language models is evolving rapidly, driven by advancements in reinforcement learning. As we look toward the future, it is essential to understand how these models can be refined and adapted to meet the demands of diverse applications.
One significant area of exploration is the integration of reinforcement learning techniques, which allow models to learn from interactions rather than solely from static datasets. This shift opens up new possibilities for training methods and enhances the model’s ability to understand and generate language based on real-world contexts.
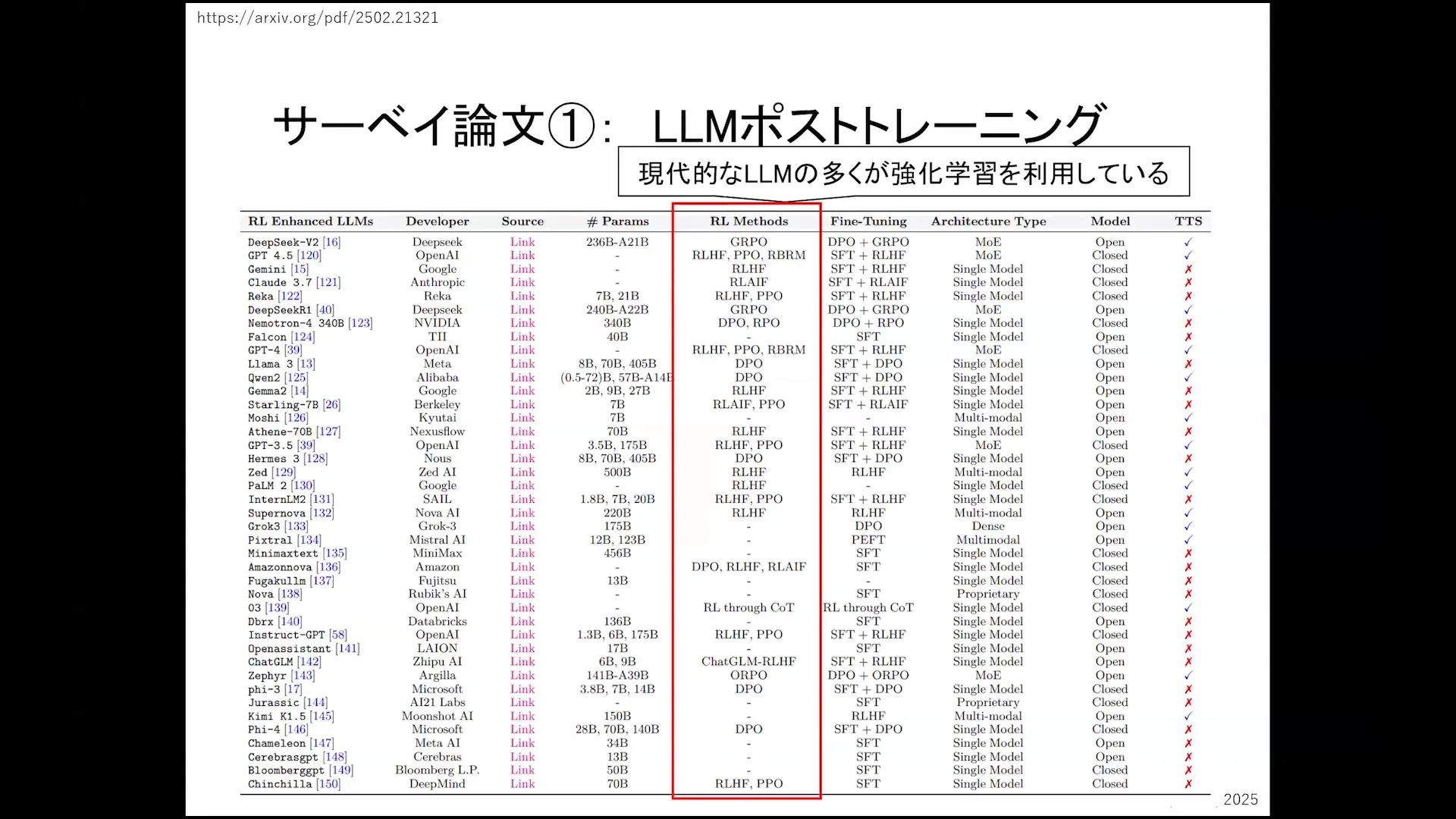
Survey of Recent Research in Large Language Models
Recent research highlights the transition from traditional supervised learning methods to more dynamic approaches, including reinforcement learning and post-training techniques. A notable study illustrates that models can achieve higher performance when trained using reinforcement learning, particularly in scenarios where conventional methods may fall short.
- Research indicates a growing emphasis on hybrid training methods that combine supervised learning with reinforcement learning.
- New frameworks are emerging that focus on fine-tuning models post-training, allowing for greater adaptability in specific domains.
- Studies have shown that models trained with reinforcement learning exhibit improved performance in novel situations, demonstrating their potential for real-world applications.

The Impact of Reinforcement Learning Techniques
The application of reinforcement learning techniques has proven to be a game-changer in the development of large language models. By enabling models to learn from their experiences, reinforcement learning enhances their ability to handle complex queries and adapt to changing contexts.
For instance, models that leverage reinforcement learning can gradually improve their performance as they interact with users, learning from both successful and unsuccessful outcomes. This iterative learning process fosters a deeper understanding of language and context.
Challenges in Domain-Specific Learning
While advancements in large language models are promising, challenges remain, particularly in domain-specific learning. Models often struggle to generalize their knowledge across different fields, leading to inconsistencies in performance.
To address these issues, researchers are focusing on developing specialized training datasets that encompass a wide range of scenarios. This approach aims to improve the model’s ability to adapt to various contexts and enhance its overall reliability.
- Domain-specific training datasets are crucial for improving model accuracy in specialized fields.
- Continuous evaluation of training methods is necessary to identify and mitigate gaps in knowledge and reasoning.
- Collaboration among researchers is essential to share insights and strategies for overcoming these challenges.
Conclusion and Future Directions
The future of large language models is bright, with ongoing research paving the way for innovative approaches and applications. As we continue to explore the capabilities of reinforcement learning, it is vital to remain aware of the challenges that lie ahead.
Moving forward, the focus should be on creating comprehensive datasets, fostering collaboration among researchers, and refining training methodologies. By addressing these areas, we can unlock the full potential of large language models and enhance their utility across various domains.
Ultimately, the integration of reinforcement learning and domain-specific training will play a pivotal role in shaping the next generation of language models. As we navigate this exciting landscape, the collaborative efforts of the research community will be key to driving progress and innovation.