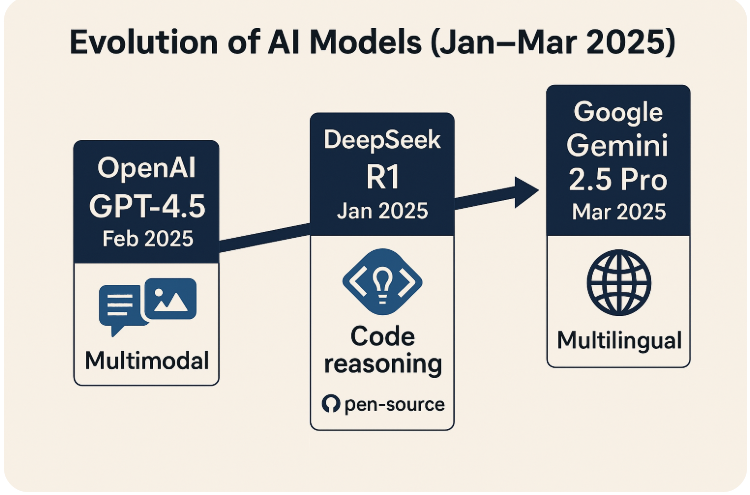
Pinecone is a managed vector database designed for AI and machine learning applications, specifically optimized for high-performance storage, retrieval, and querying of vector embeddings. It enables developers to build and deploy applications that rely on similarity search, real-time recommendations, and retrieval-augmented generation (RAG) for large language models (LLMs).
1. Platform Name and Provider
- Name: Pinecone
- Provider: Pinecone Systems, Inc.
2. Overview
- Description: Pinecone is a managed vector database designed for AI and machine learning applications, specifically optimized for high-performance storage, retrieval, and querying of vector embeddings. It enables developers to build and deploy applications that rely on similarity search, real-time recommendations, and retrieval-augmented generation (RAG) for large language models (LLMs).
3. Key Features
- High-Performance Vector Database: Pinecone stores and manages vector embeddings efficiently, enabling fast similarity searches, making it ideal for recommendation engines, search engines, and RAG.
- Scalable and Fully Managed: Pinecone is fully managed, handling infrastructure scaling and maintenance, allowing users to focus on application development without worrying about operational overhead.
- Real-Time Similarity Search: Supports real-time vector search, which is critical for applications that require immediate and relevant results based on similarity, such as personalized recommendations or dynamic information retrieval.
- Hybrid Filtering: Pinecone supports hybrid search, combining vector search with metadata-based filtering, allowing users to refine search results based on both content and attributes.
- Integration with AI and ML Models: Seamlessly integrates with popular LLMs and ML models from OpenAI, Hugging Face, and other platforms, making it easy to implement embedding-based search and retrieval functionalities.
- Multi-Cloud and Region Availability: Pinecone can be deployed across different cloud regions and providers, offering flexibility and compliance for global applications.
4. Supported Tasks and Use Cases
- Retrieval-augmented generation (RAG) for LLMs
- Real-time recommendation engines
- Semantic search and similarity search
- Personalized content and product recommendations
- Knowledge retrieval and question answering systems
5. Model Access and Customization
- While Pinecone is not a model provider, it works seamlessly with external LLMs and ML models, allowing developers to store and retrieve embeddings generated by various models. Customization is available in search filtering and indexing options to optimize retrieval for specific use cases.
6. Data Integration and Connectivity
- Pinecone integrates with multiple machine learning frameworks and data sources, allowing easy ingestion of embeddings and real-time connection with external data, supporting a seamless retrieval pipeline for AI applications.
7. Workflow Creation and Orchestration
- The platform supports embedding-based workflows where data is processed, indexed, and retrieved based on similarity search and relevance, which is useful for applications that combine multiple search and retrieval steps.
8. Memory Management and Continuity
- Pinecone functions as a persistent memory for embeddings, retaining vectors and metadata over time. This allows applications to maintain long-term context and retrieve information with continuity, beneficial for conversational AI and historical data analysis.
9. Security and Privacy
- Pinecone offers enterprise-grade security features, including data encryption, role-based access control (RBAC), and compliance with industry standards, making it suitable for handling sensitive and proprietary data in enterprise environments.
10. Scalability and Extensions
- Pinecone is highly scalable, designed to handle massive datasets with billions of vectors and high query throughput. It also offers flexible configuration options for custom scaling and extension with additional data types or metadata fields as required.
11. Target Audience
- Pinecone is tailored for data scientists, ML engineers, and enterprises building applications that rely on fast, scalable vector search, particularly in fields like recommendation systems, information retrieval, and conversational AI.
12. Pricing and Licensing
- Pinecone offers a usage-based pricing model with a free tier for initial experimentation and paid plans that scale based on storage, query volume, and other advanced features for production environments.
13. Example Use Cases or Applications
- RAG for Customer Support: Supports retrieval-augmented generation to improve customer service by pulling relevant information in real time.
- Product Recommendations: Embedding-based similarity search for personalized product recommendations based on user behavior and interests.
- Knowledge Base Retrieval: Stores and retrieves embeddings of enterprise documents to answer questions with accurate, contextual responses.
- Semantic Search for Content Platforms: Enables relevant, similarity-based content recommendations on media or publishing platforms.
14. Future Outlook
- Pinecone is expected to expand its hybrid search capabilities, indexing flexibility, and cloud options, making it an increasingly robust choice for real-time, large-scale embedding retrieval across various AI applications.
15. Website and Resources
- Official Website: Pinecone
- Documentation: Pinecone Documentation
- GitHub Repository: Pinecone on GitHub