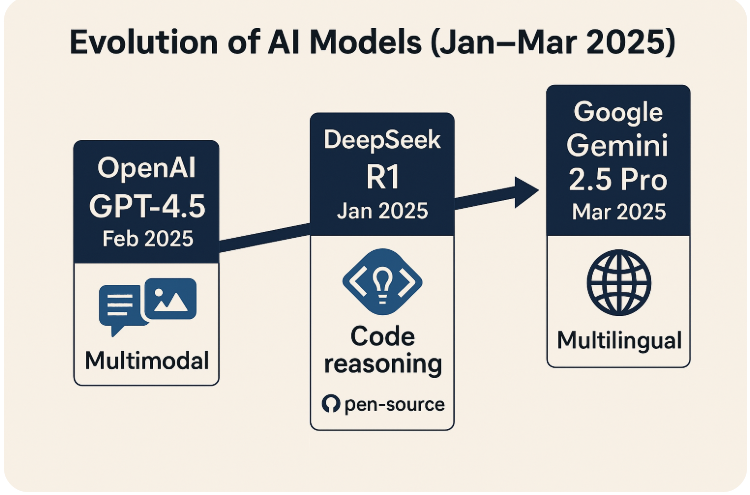
GPTCache is an open-source caching library designed specifically for large language model (LLM) responses, enabling efficient storage and retrieval of previously generated responses. It aims to reduce response latency and costs associated with repeated LLM queries, providing developers with a high-performance cache that optimizes LLM-based applications by reusing similar responses.
1. Platform Name and Provider
- Name: GPTCache
- Provider: Open-source project, maintained by the GPTCache community.
2. Overview
- Description: GPTCache is an open-source caching library designed specifically for large language model (LLM) responses, enabling efficient storage and retrieval of previously generated responses. It aims to reduce response latency and costs associated with repeated LLM queries, providing developers with a high-performance cache that optimizes LLM-based applications by reusing similar responses.
3. Key Features
- Efficient Response Caching: Caches LLM responses to avoid redundant requests, minimizing latency and reducing costs by reusing previously generated outputs for similar prompts.
- Similarity-Based Retrieval: Uses advanced similarity metrics to retrieve relevant cached responses, allowing slight variations in input prompts to benefit from existing cached results.
- Customizable Cache Policies: Supports various caching strategies, including time-based expiration, frequency-based caching, and custom caching policies, enabling developers to tailor caching behavior to specific use cases.
- Integration with Popular LLM Providers: Compatible with LLMs from OpenAI, Hugging Face, and other major providers, making it easy to incorporate into existing applications without major reconfiguration.
- Real-Time Cache Performance Monitoring: Tracks cache hit rates, response times, and other metrics, giving users insights into cache performance and helping optimize cache settings for maximum efficiency.
- Flexible Storage Options: Supports different storage backends for caching, including in-memory storage for low-latency needs and databases like SQLite and Redis for persistent caching across sessions.
4. Supported Tasks and Use Cases
- Cost reduction in high-volume LLM applications
- Latency reduction for real-time LLM-based applications
- Optimized response handling in chatbots and virtual assistants
- Improved efficiency in prompt-heavy research or development workflows
- Enhanced response management for customer support systems
5. Model Access and Customization
- GPTCache integrates with various LLMs and allows customization of cache policies, similarity thresholds, and response expiration, enabling users to fine-tune cache behavior based on application-specific requirements.
6. Data Integration and Connectivity
- The platform supports integration with popular LLMs and is compatible with various storage backends, providing users flexibility in choosing storage solutions that meet latency or persistence needs.
7. Workflow Creation and Orchestration
- While focused on caching, GPTCache supports multi-turn workflows by caching responses across conversations, ensuring that repeated interactions or queries benefit from efficient retrieval. It is particularly useful for applications that handle repetitive prompts within defined workflows.
8. Memory Management and Continuity
- GPTCache offers memory-efficient caching with adjustable expiration policies and supports in-memory or persistent storage, allowing it to retain continuity across sessions for frequently accessed responses, while also managing memory usage effectively.
9. Security and Privacy
- GPTCache can be deployed locally or in secure environments, providing control over sensitive data handling and caching. When using external storage, it supports secure connections to maintain data privacy and integrity.
10. Scalability and Extensions
- Designed to be highly scalable, GPTCache can handle large volumes of cached responses and integrates well with distributed architectures, making it suitable for enterprise-scale applications. Its open-source framework allows extensions and integration with custom storage solutions or additional LLM providers.
11. Target Audience
- GPTCache is targeted at developers, data scientists, and organizations using LLMs in high-volume or high-frequency applications, particularly those focused on reducing costs, improving response times, and enhancing application efficiency through caching.
12. Pricing and Licensing
- GPTCache is open-source and free to use under an open-source license, allowing for deployment in personal and commercial projects without licensing costs. Any costs would relate to chosen storage solutions or LLM API usage.
13. Example Use Cases or Applications
- E-commerce Customer Support: Reduces response time and costs by caching frequently asked questions or common inquiries, enabling faster responses to customer questions.
- Educational Tutoring Applications: Provides efficient response caching for tutoring applications that handle repeated questions or similar inquiries, reducing redundancy.
- Product Recommendation Engines: Caches product descriptions or frequently requested recommendations, improving response speed in e-commerce chatbots.
- Knowledge Retrieval Systems: Optimizes access to commonly retrieved information in knowledge bases, enhancing efficiency for customer support and internal help desks.
- Research and Development: Minimizes redundant LLM queries during testing, experimentation, and prompt engineering, reducing costs associated with development.
14. Future Outlook
- GPTCache is expected to expand with more advanced similarity-based retrieval, support for additional storage backends, and enhanced cache management tools, making it even more versatile for a wider range of LLM-based applications.
15. Website and Resources
- GitHub Repository: GPTCache on GitHub
- Documentation: Available within the GitHub repository